Goal-Conditioned F-Advantage Regression (GoFAR)
GoFAR is a novel regression-based offline GCRL algorithm derived from a state-occupancy matching perspective; the key intuition is that the goal-reaching task can be formulated as a state-occupancy matching problem between a dynamics-abiding imitator agent and an expert agent that directly teleports to the goal (see Figure on the right.)
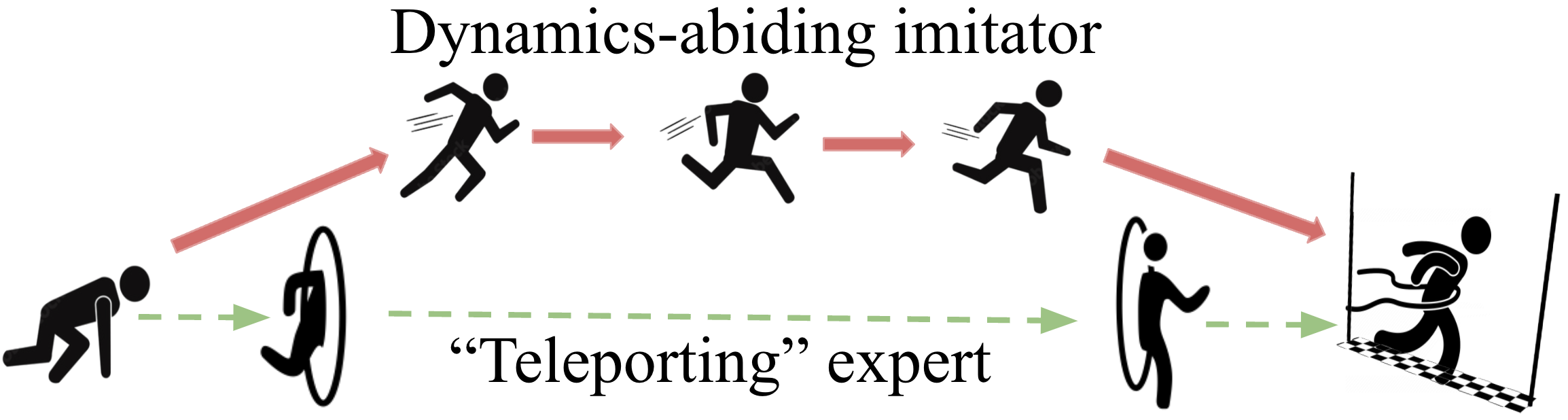
Leveraging this intuition, we pose a f-divergence regularized optimization problem over valid policy occupancy distributions. This optimization problem is difficult to solve; however, its dual problem is surprisingly simple and tractable. Therefore, we solve the dual problem and obtain the optimal (resp. converged) value function. A transformation of this optimal value function can be shown to be the optimal importance weights, using which we train the policy via supervised regression.

Uninterleaved Optimization
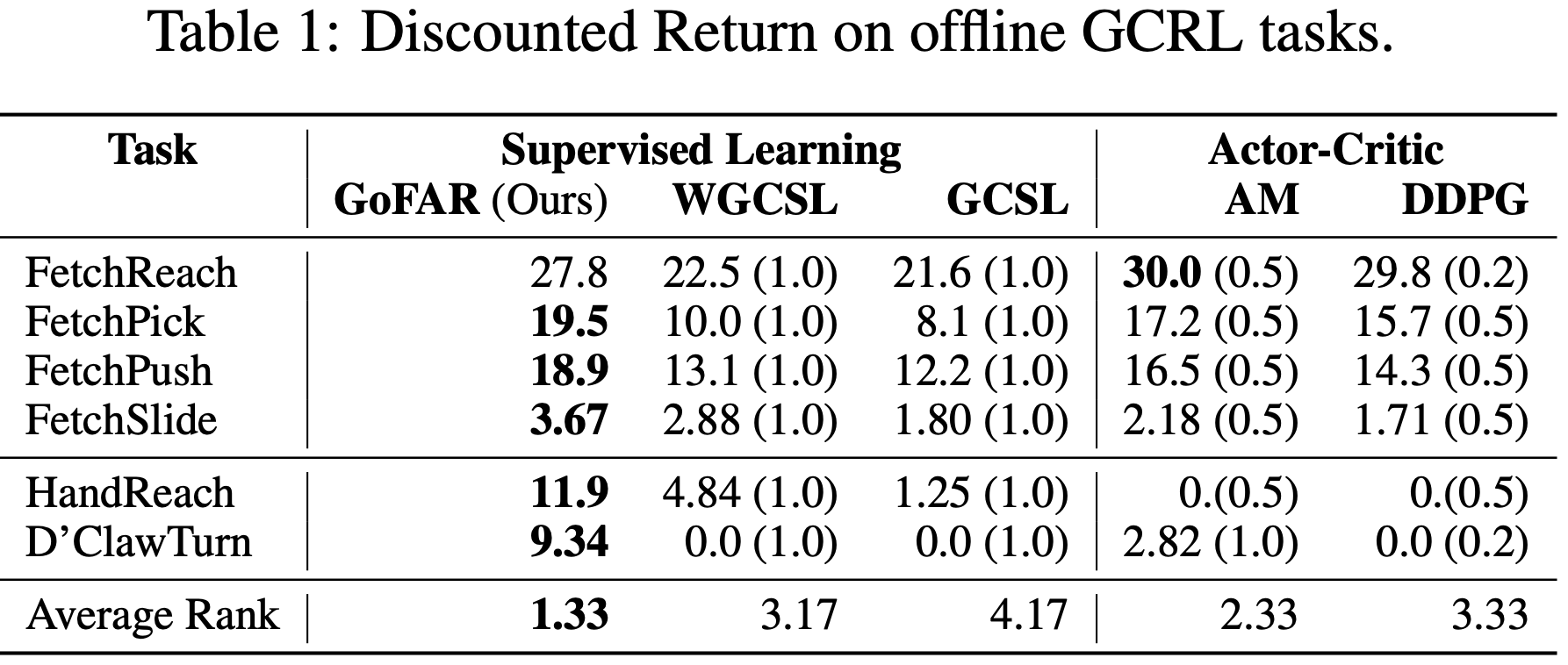
GoFAR does not train its policy until its value function has converged. This confers uninterleaved optimization that is more stable than prior actor-critic based methods in the offline setting. This feature enables GoFAR to obtain state-of-art performance on a variety of offline goal-conditioned continuous control tasks.
Relabeling-Free Goal-Conditioned RL
A distinct feature of GoFAR is that it does not utilize hindsight goal-relabeling (e.g., HER), a crucial component for all prior methods for credit assignment. In fact, GoFAR achieves optimal goal-weighting as a by-product of its dual optimization approach.
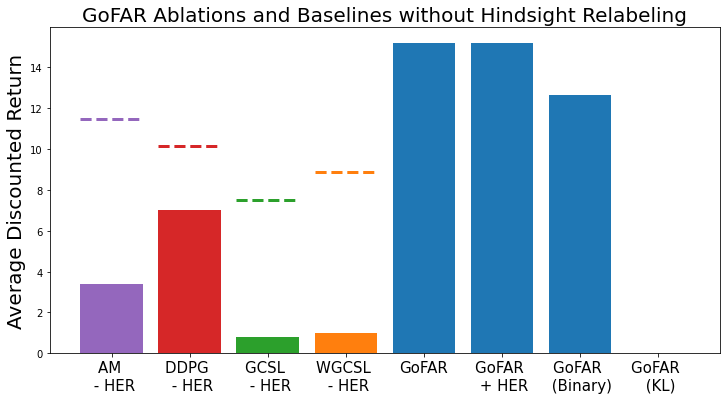
A consequence of GoFAR's relabeling-free optimization is that its performance is more robust in stochastic environments, in which hindsight relabeling suffers from "false positives". This observation is experimentally validated in the following experiment, in which we see that larger noise rates significantly hurt the baselines (which all use hindsight relabeling) more than GoFAR.
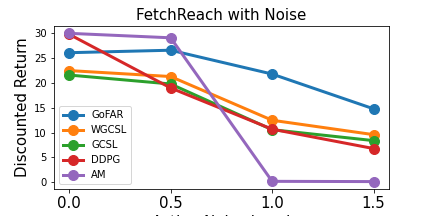
Noise Rate.
Zero-Shot Goal-Conditioned Plan Transfer
GoFAR's value function objective, assuming deterministic transitions, does not depend on the action labels. Therefore, we can use it to train an agent-independent goal-centric value function, and zero-shot transfer to a new target domain as a hierarchical planner. In the experiment below, we show that GoFAR can enhance a low-level controller to reach distant goals that it is not designed for.